Определяется как обобщающая характеристика размеров вариации признака в совокупности. Оно равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической, т.е. корень из и может быть найдена так:
1. Для первичного ряда:
2. Для вариационного ряда:

Преобразование формулы среднего квадратичного отклонени приводит ее к виду, более удобному для практических расчетов:
Среднее квадратичное отклонение определяет на сколько в среднем отклоняются конкретные варианты от их среднего значения, и к тому же является абсолютной мерой колеблемости признака и выражается в тех же единицах, что и варианты, и поэтому хорошо интерпретируется.
Примеры нахождения cреднего квадратического отклонения: ,
Для альтернативных признаков формула среднего квадратичного отклонения выглядит так:
![]()
где р - доля единиц в совокупности, обладающих определенным признаком;
q - доля единиц, не обладающих этим признаком.
Понятие среднего линейного отклонения
Среднее линейное отклонение определяется как средняя арифметическая абсолютных значений отклонений отдельных вариантов от .
1. Для первичного ряда:

2. Для вариационного ряда:
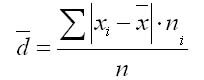
где сумма n - сумма частот вариационного ряда .
Пример нахождения cреднего линейного отклонения:
Преимущество среднего абсолютного отклонения как меры рассеивания перед размахом вариации, очевидно, так как эта мера основана на учете всех возможных отклонений. Но этот показатель имеет существенные недостатки. Произвольные отбрасывания алгебраических знаков отклонений могут привести к тому, что математические свойства этого показателя являются далеко не элементарными. Это сильно затрудняет использование среднего абсолютного отклонения при решении задач, связанных с вероятностными расчетами.
Поэтому среднее линейное отклонение как мера вариации признака применяется в статистической практике редко, а именно тогда, когда суммирование показателей без учета знаков имеет экономический смысл. С его помощью, например, анализируется оборот внешней торговли, состав работающих, ритмичность производства и т. д.
Среднее квадратическое
Среднее квадратическое применяется , например, для вычисления средней величины сторон n квадратных участков, средних диаметров стволов, труб и т. д. Она подразделяется на два вида.
Средняя квадратичная простая. Если при замене индивидуальных величин признака на среднюю величину необходимо сохранить неизменной сумму квадратов исходных величин, то средняя будет являться квадратичной средней величиной.
Она является квадратным корнем из частного от деления суммы квадратов отдельных значений признака на их число:
Средняя квадратичная взвешенная вычисляется по формуле:

где f - признак веса.
Средняя кубическая
Средняя кубическая применяется
, например, при определении средней длины стороны и кубов. Она подразделяется на два вида.
Средняя кубическая простая:


При расчете средних величин и дисперсии в интервальных рядах распределения истинные значения признака заменяются центральными значениями интервалов, которые отличны от средней арифметической значений, включенных в интервал. Это приводит к возникновению систематической погрешности при расчете дисперсии. В.Ф. Шеппард определил, что погрешность в расчете дисперсии , вызванная применением сгруппированных данных, составляет 1/12 квадрата величины интервала как в сторону повышения, так и в сторону понижения величины дисперсии.
Поправка Шеппарда должна применяться, если распределение близко к нормальному, относится к признаку с непрерывным характером вариации, построено по значительному количеству исходных данных (n > 500). Однако исходя из того, что в ряде случаев обе погрешности, действуя в разных направлениях компенсируют друг друга, можно иногда отказаться от введения поправок.
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность и тем более типичной будет средняя величина.
В практике статистики часто возникает необходимость сравнения вариаций различных признаков. Например, большой интерес представляет сравнение вариаций возраста рабочих и их квалификации, стажа работы и размера заработной платы, себестоимости и прибыли, стажа работы и производительности труда и т.д. Для таких сопоставлений показатели абсолютной колеблемости признаков непригодны: нельзя сравнивать колеблемость стажа работы, выраженного в годах, с вариацией заработной платы, выраженной в рублях.
Для осуществления таких сравнений, а также сравнений колеблемости одного и того же признака в нескольких совокупностях с разными средним арифметическим используется относительный показатель вариации - коэффициент вариации.
Структурные средние
Для характеристики центральной тенденции в статистических распределениях не редко рационально вместе со средней арифметической использовать некоторое значение признака X, которое в силу определенных особенностей расположения в ряду распределения может характеризовать его уровень.
Это особенно важно тогда, когда в ряду распределения крайние значения признака имеют нечеткие границы. В связи с этим точное определение средней арифметической, как правило, невозможно, либо очень сложно. В таких случаях средний уровень можно определить, взяв, например, значение признака, которое расположено в середине ряда частот или которое чаще всего встречается в текущем ряду.
Такие значения зависят только от характера частот т. е. от структуры распределения. Они типичны по месту расположения в ряду частот, поэтому такие значения рассматриваются в качестве характеристик центра распределения и поэтому получили определение структурных средних. Они применяются для изучения внутреннего строения и структуры рядов распределения значений признака. К таким показателям относятся .
Средняя величина - это обобщающий показатель статистической совокупности, который погашает индивидуальные различия значений статистических величин, позволяя сравнивать разные совокупности между собой.
Существует 2 класса средних величин: и .
К структурным средним относятся мода и медиана , но наиболее часто применяются степенные средние различных видов.
Степенные средние величины
Степенные средние могут быть простыми и взвешенными .
Простая средняя величина рассчитывается при наличии двух и более несгруппированных статистических величин, расположенных в произвольном порядке по следующей общей формуле:
Взвешенная средняя величина рассчитывается по сгруппированным статистическим величинам с использованием следующей общей формулы:

Где X – значения отдельных статистических величин или середин группировочных интервалов;
m - показатель степени, от значения которого зависят следующие виды степенных средних величин
:
при m = -1 ;
при m = 0 ;
при m = 1 ;
при m = 2 ;
при m = 3 .
Используя общие формулы простой и взвешенной средних при разных показателях степени m, получаем частные формулы каждого вида, которые будут далее подробно рассмотрены.
Средняя арифметическая
Средняя арифметическая - это самая часто используемая средняя величина, которая получается, если подставить в общую формулу m=1. Средняя арифметическая простая имеет следующий вид:
![]()
Где X - значения величин, для которых необходимо рассчитать среднее значение; N - общее количество значений X (число единиц в изучаемой совокупности).
Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Рассчитаем средний балл по формуле средней арифметической простой: (3+4+4+5)/4 = 16/4 = 4.
Средняя арифметическая взвешенная имеет следующий вид:

Где f - количество величин с одинаковым значением X (частота).
Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Рассчитаем средний балл по формуле средней арифметической взвешенной: (3*1 + 4*2 + 5*1)/4 = 16/4 = 4.
Если значения X заданы в виде интервалов, то для расчетов используют середины интервалов X, которые определяются как полусумма верхней и нижней границ интервала. А если у интервала X отсутствует нижняя или верхняя граница (открытый интервал), то для ее нахождения применяют размах (разность между верхней и нижней границей) соседнего интервала X.
Например, на предприятии 10 работников со стажем работы до 3 лет, 20 - со стажем от 3 до 5 лет, 5 работников - со стажем более 5 лет. Тогда рассчитаем средний стаж работников по формуле средней арифметической взвешенной, приняв в качестве X середины интервалов стажа (2, 4 и 6 лет):
(2*10+4*20+6*5)/(10+20+5) = 3,71 года.
Средняя арифметическая применяется чаще всего, но бывают случаи, когда необходимо применение других видов средних величин. Рассмотрим такие случаи далее.
Средняя гармоническая
Средняя гармоническая применяется, когда исходные данные не содержат частот f по отдельным значениям X, а представлены как их произведение Xf. Обозначив Xf=w, выразим f=w/X, и, подставив эти обозначения в формулу средней арифметической взвешенной, получим формулу средней гармонической взвешенной:

Таким образом, средняя гармоническая взвешенная применяется тогда, когда неизвестны частоты f, а известно w=Xf. В тех случаях, когда все w=1, то есть индивидуальные значения X встречаются по 1 разу, применяется формула средней гармонической простой:

Например, автомобиль ехал из пункта А в пункт Б со скоростью 90 км/ч, а обратно - со скоростью 110 км/ч. Для определения средней скорости применим формулу средней гармонической простой, так как в примере дано расстояние w 1 =w 2 (расстояние из пункта А в пункт Б такое, же как и из Б в А), которое равно произведению скорости (X) на время (f). Средняя скорость = (1+1)/(1/90+1/110) = 99 км/ч.
Средняя геометрическая
Средняя геометрическая применяется при определении средних относительных изменений, о чем сказано в теме Ряды динамики . Геометрическая средняя величина дает наиболее точный результат осреднения, если задача стоит в нахождении такого значения X, который был бы равноудален как от максимального, так и от минимального значения X.
Например, в период с 2005 по 2008 годы индекс инфляции в России составлял: в 2005 году - 1,109; в 2006 - 1,090; в 2007 - 1,119; в 2008 - 1,133. Так как индекс инфляции - это относительное изменение (индекс динамики), то рассчитывать среднее значение нужно по средней геометрической: (1,109*1,090*1,119*1,133)^(1/4) = 1,1126, то есть за период с 2005 по 2008 ежегодно цены росли в среднем на 11,26%. Ошибочный расчет по средней арифметической дал бы неверный результат 11,28%.
Средняя квадратическая
Средняя квадратическая применяется в тех случая, когда исходные значения X могут быть как положительными, так и отрицательными, например при расчете средних отклонений.
![]()
Главной сферой применения квадратической средней является измерение вариации значений X, о чем пойдет речь .
Средняя кубическая
Средняя кубическая применяется крайне редко, например, при расчете индексов нищеты населения для развивающихся стран (ИНН-1) и для развитых (ИНН-2), предложенных и рассчитываемых ООН.
![]()
Структурные средние величины
К наиболее часто используемым структурным средним относятся и .
Статистическая мода
Статистическая мода - это наиболее часто повторяющееся значение величины X в статистической совокупности.
Если X задан дискретно , то мода определяется без вычисления как значение признака с наибольшей частотой. В статистической совокупности бывает 2 и более моды, тогда она считается бимодальной (если моды две) или мультимодальной (если мод более двух), и это свидетельствует о неоднородности совокупности.
Например, на предприятии работает 16 человек: 4 из них - со стажем 1 год, 3 человека - со стажем 2 года, 5 - со стажем 3 года и 4 человека - со стажем 4 года. Таким образом, модальный стаж Мо=3 года, поскольку частота этого значения максимальна (f=5).
Если X задан равными интервалами , то сначала определяется модальный интервал как интервал с наибольшей частотой f. Внутри этого интервала находят условное значение моды по формуле:
![]()
Где Мо – мода;
Х НМо – нижняя граница модального интервала;
h Мо – размах модального интервала (разность между его верхней и нижней границей);
f Мо – частота модального интервала;
f Мо-1 – частота интервала, предшествующего модальному;
f Мо+1 – частота интервала, следующего за модальным.
Например, на предприятии 10 работников со стажем работы до 3 лет, 20 - со стажем от 3 до 5 лет, 5 работников - со стажем более 5 лет. Рассчитаем модальный стаж работы в модальном интервале от 3 до 5 лет: Мо = 3 + 2*(20-10)/(2*20-10-5) = 3,8 (года).
Если размах интервалов h разный, то вместо частот f необходимо использовать плотности интервалов, рассчитываемые путем деления частот f на размах интервала h.
Статистическая медиана
Статистическая медиана – это значение величины X, которое делит упорядоченную по возрастанию или убыванию статистическую совокупность на 2 равных по численности части. В итоге у одной половины значение больше медианы, а у другой - меньше медианы.
Если X задан дискретно , то для определения медианы все значения нумеруются от 0 до N в порядке возрастания , тогда медиана при четном числе N будет лежать посередине между X c номерами 0,5N и (0,5N+1), а при нечетном числе N будет соответствовать значению X с номером 0,5(N+1).
Например, имеются данные о возрасте студентов-заочников в группе из 10 человек - X: 18, 19, 19, 20, 21, 23, 23, 25, 28, 30 лет. Эти данные уже упорядочены по возрастанию, а их количество N=10 - четное, поэтому медиана будет находиться между X с номерами 0,5*10=5 и (0,5*10+1)=6, которым соответствуют значения X 5 =21 и X 6 =23, тогда медиана: Ме = (21+23)/2 = 22 (года).
Если X задан в виде равных интервалов , то сначала определяется медианный интервал (интервал, в котором заканчивается одна половина частот f и начинается другая половина), в котором находят условное значение медианы по формуле:
![]()
Где Ме – медиана;
Х НМе – нижняя граница медианного интервала;
h Ме – размах медианного интервала (разность между его верхней и нижней границей);
f Ме – частота медианного интервала;
f Ме-1 – сумма частот интервалов, предшествующих медианному.
В ранее рассмотренном примере при расчете модального стажа (на предприятии 10 работников со стажем работы до 3 лет, 20 - со стажем от 3 до 5 лет, 5 работников - со стажем более 5 лет) рассчитаем медианный стаж. Половина общего числа работников составляет (10+20+5)/2 = 17,5 и находится в интервале от 3 до 5 лет, а в первом интервале до 3 лет - только 10 работников, а в первых двух - (10+20)=30, что больше 17,5, значит интервал от 3 до 5 лет - медианный. Внутри него определяем условное значение медианы: Ме = 3+2*(0,5*30-10)/20 = 3,5 (года).
Также как и в случае с модой, при определении медианы если размах интервалов h разный, то вместо частот f необходимо использовать плотности интервалов, рассчитываемые путем деления частот f на размах интервала h.
Показатели вариации
Вариация - это различие значений величин X у отдельных единиц статистической совокупности. Для изучения силы вариации рассчитывают следующие показатели вариации : , , , , .
Размах вариации
Размах вариации – это разность между максимальным и минимальным значениями X из имеющихся в изучаемой статистической совокупности:
![]()
Недостатком показателя H является то, что он показывает только максимальное различие значений X и не может измерять силу вариации во всей совокупности.
Cреднее линейное отклонение
Cреднее линейное отклонение - это средний модуль отклонений значений X от среднего арифметического значения. Его можно рассчитывать по формуле средней арифметической простой - получим :
![]()
Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. = 4. Рассчитаем среднее линейное отклонение простое: Л = (|3-4|+|4-4|+|4-4|+|5-4|)/4 = 0,5.
Если исходные данные X сгруппированы (имеются частоты f), то расчет среднего линейного отклонения выполняется по формуле средней арифметической взвешенной - получим :

Вернемся к примеру про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. = 4 и = 0,5. Рассчитаем среднее линейное отклонение взвешенное: Л = (|3-4|*1+|4-4|*2+|5-4|*1)/4 = 0,5.
Линейный коэффициент вариации
Линейный коэффициент вариации - это отношение среднего линейного отклонение к средней арифметической:
С помощью линейного коэффициента вариации можно сравнивать вариацию разных совокупностей, потому что в отличие от среднего линейного отклонения его значение не зависит от единиц измерения X.
В рассматриваемом примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, линейный коэффициент вариации составит 0,5/4 = 0,125 или 12,5%.
Дисперсия
Дисперсия - это средний квадрат отклонений значений X от среднего арифметического значения. Дисперсию можно рассчитывать по формуле средней арифметической простой - получим дисперсию простую :
![]()
В уже знакомом нам примере про студента, который сдал 4 экзамена и получил оценки: 3, 4, 4 и 5, = 4. Тогда дисперсия простая Д = ((3-4) 2 +(4-4) 2 +(4-4) 2 +(5-4) 2)/4 = 0,5.
Если исходные данные X сгруппированы (имеются частоты f), то расчет дисперсии выполняется по формуле средней арифметической взвешенной - получим дисперсию взвешенную :

В рассматриваемом примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, рассчитаем дисперсию взвешенную: Д = ((3-4) 2 *1+(4-4) 2 *2+(5-4) 2 *1)/4 = 0,5.
Если преобразовать формулу дисперсии (раскрыть скобки в числителе, почленно разделить на знаменатель и привести подобные), то можно получить еще одну формулу для ее расчета как разность средней квадратов и квадрата средней:
Еще проще можно найти среднее квадратическое отклонение , если предварительно рассчитана дисперсия, как корень квадратный из нее:
В примере про студента, в котором выше , найдем среднее квадратическое отклонение как корень квадратный из нее:.
Квадратический коэффициент вариации
Квадратический коэффициент вариации - это самый популярный относительный показатель вариации:
Критериальным значением квадратического коэффициента вариации V служит 0,333 или 33,3%, то есть если V меньше или равен 0,333 - вариация считает слабой, а если больше 0,333 - сильной. В случае сильной вариации изучаемая статистическая совокупность считается неоднородной , а средняя величина - нетипичной и ее нельзя использовать как обобщающий показатель этой совокупности.
В примере про студента, в котором выше , найдем квадратический коэффициент вариации V = 0,707/4 = 0,177, что меньше критериального значения 0,333, значит вариация слабая и равна 17,7%.
Х i - случайные (текущие) величины;
X̅ – среднее значение случайных величин по выборке, рассчитывается по формуле:

Итак, дисперсия - это средний квадрат отклонений . То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат , складывается и затем делится на количество значений в данной совокупности.
Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, мы просто рассчитываем среднюю арифметическую.
Разгадка магического слова «дисперсия» заключается всего в этих трех словах: средний – квадрат – отклонений.
Среднее квадратичное отклонение (СКО)
Извлекая из дисперсии квадратный корень, получаем, так называемое «среднеквадратичное отклонение». Встречаются названия «стандартное отклонение» или «сигма» (от названия греческой буквыσ .). Формула среднего квадратичного отклонения имеет вид:
Итак, дисперсия – это сигма в квадрате, или – среднее квадратичное отклонение в квадрате.
Среднеквадратичное отклонение, очевидно, также характеризует меру рассеивания данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными, так как единицы измерения у них одинаковые (это явствует из формулы расчета). Размах вариации – это разница между крайними значениями. Среднеквадратичное отклонение, как мера неопределенности, также участвует во многих статистических расчетах. С ее помощью устанавливают степень точности различных оценок и прогнозов. Если вариация очень большая, то стандартное отклонение тоже получится большим, следовательно, и прогноз будет неточным, что выразится, к примеру, в очень широких доверительных интервалах.
Поэтому в методах статистической обработки данных в оценках объектов недвижимости в зависимости от необходимой точности поставленной задачи используют правило двух или трех сигм.
Для сравнения правила двух сигм и правила трех сигм используем формулу Лапласа:
![]() Ф - Ф ,
Ф - Ф ,
где Ф(x) – функция Лапласа;
Минимальное значение
β = максимальное значение
s = значение сигмы (среднее квадратичное отклонение)
a = среднее значение
В этом случае используется частный вид формулы Лапласа когда границы α и β значений случайной величины X равно отстоят от центра распределения a = M(X) на некоторую величину d: a = a-d, b = a+d.
 Или
Или
  (1)
Формула (1) определяет вероятность заданного отклонения d случайной величины X с нормальным законом распределения от ее математического ожидания М(X) = a.
Если в формуле (1) принять последовательно d = 2s и d = 3s, то получим:
(2),
(3). (1)
Формула (1) определяет вероятность заданного отклонения d случайной величины X с нормальным законом распределения от ее математического ожидания М(X) = a.
Если в формуле (1) принять последовательно d = 2s и d = 3s, то получим:
(2),
(3).
|
Правило двух сигм
Почти достоверно (с доверительной вероятностью 0,954) можно утверждать, что все значения случайной величины X с нормальным законом распределения отклоняются от ее математического ожидания M(X) = a на величину, не большую 2s (двух средних квадратических отклонений). Доверительной вероятностью (Pд) называют вероятность событий, которые условно принимаются за достоверные (их вероятность близка к 1).
Проиллюстрируем правило двух сигм геометрически. На рис. 6 изображена кривая Гаусса с центром распределения а. Площадь, ограниченная всей кривой и осью Оx, равна 1 (100%), а площадь криволинейной трапеции между абсциссами а–2s и а+2s, согласно правилу двух сигм, равна 0,954 (95,4% от всей площади). Площадь заштрихованных участков равна 1-0,954 = 0,046 (»5% от всей площади). Эти участки называют критической областью значений случайной величины. Значения случайной величины, попадающие в критическую область, маловероятны и на практике условно принимаются за невозможные.

Вероятность условно невозможных значений называют уровнем значимости случайной величины. Уровень значимости связан с доверительной вероятностью формулой:
где q – уровень значимости, выраженный в процентах.
Правило трех сигм
При решении вопросов, требующих большей надежности, когда доверительную вероятность (Pд) принимают равной 0,997 (точнее - 0,9973), вместо правила двух сигм, согласно формуле (3), используют правило трех сигм.
Согласно правилу трех сигм при доверительной вероятности 0,9973 критической областью будет область значений признака вне интервала (а-3s, а+3s). Уровень значимости составляет 0,27%.
Другими словами, вероятность того, что абсолютная величина отклонения превысит утроенное среднее квадратическое отклонение, очень мала, а именно равна 0,0027=1-0,9973. Это означает, что лишь в 0,27% случаев так может произойти. Такие события, исходя из принципа невозможности маловероятных событий, можно считать практически невозможными. Т.е. выборка высокоточная.
В этом и состоит сущность правила трех сигм:
Если случайная величина распределена нормально, то абсолютная величина ее отклонения от математического ожидания не превосходит утроенного среднего квадратического отклонения (СКО).
На практике правило трех сигм применяют так: если распределение изучаемой случайной величины неизвестно, но условие, указанное в приведенном правиле, выполняется, то есть основание предполагать, что изучаемая величина распределена нормально; в противном случае она не распределена нормально.
Уровень значимости принимают в зависимости от дозволенной степени риска и поставленной задачи. Для оценки недвижимости обычно принимается менее точная выборка, следуя правилу двух сигм.
Цель данной статьи показать , как математические формулы, с которыми вы можете столкнуться в книгах и статьях, разложить на элементарные функции в Excel.
В данной статье мы разберем формулы среднеквадратического отклонения и дисперсии и рассчитаем их в Excel
.
Перед тем как переходить к расчету среднеквадратического отклонения и разбирать формулу, желательно разобраться в элементарных статистических показателях и обозначениях.
Рассматривая формулы моделей прогнозирования, мы встретимся со следующими показателями:

Например, у нас есть временной ряд - продажи по неделям в шт.
|
Неделя |
||||||||||
|
Отгрузка, шт |
Для этого временного ряда i=1, n=10
,  ,
,
Рассмотрим формулу среднего значения:
|
Неделя |
||||||||||
|
Отгрузка, шт |
Для нашего временного ряда определим среднее значение

Также для выявления тенденций помимо среднего значения представляет интерес и то, насколько наблюдения разбросаны относительно среднего. Среднеквадратическое отклонение показывает меру отклонения наблюдений относительно среднего.
Формула расчета среднеквадратического отклонение для выборки следующая:

Разложим формулу на составные части и рассчитаем среднеквадратическое отклонение в Excel на примере нашего временного ряда.
1. Рассчитаем среднее значение для этого воспользуемся формулой Excel =СРЗНАЧ(B11:K11)

2. Определим отклонение каждого значения ряда относительно среднего

для первой недели = 6-10=-4
для второй недели = 10-10=0
для третей = 7-1=-3 и т.д.
3. Для каждого значения ряда определим квадрат разницы отклонения значений ряда относительно среднего
для первой недели = (-4)^2=16
для второй недели = 0^2=0
для третей = (-3)^2=9 и т.д.
4. Рассчитаем сумму квадратов отклонений значений относительно среднего  с помощью формулы =СУММ(ссылка на диапазон (ссылка на диапазон с )
с помощью формулы =СУММ(ссылка на диапазон (ссылка на диапазон с )
Среднеквадрати́ческое отклоне́ние (среднее квадрати́ческое отклоне́ние , среднеквадрати́чное отклоне́ние , квадрати́чное отклоне́ние , станда́ртное отклоне́ние , станда́ртный разбро́с ) - в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания . Обычно указанные термины означают квадратный корень из дисперсии случайной величины, но иногда могут означать тот или иной вариант оценки этого значения.
В литературе обычно обозначают греческой буквой σ {\displaystyle \sigma } (сигма).
Основные сведения
Среднеквадратическое отклонение определяется как квадратный корень из дисперсии случайной величины : σ = D [ X ] {\displaystyle \sigma ={\sqrt {D[X]}}} .
Среднеквадратическое отклонение измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического , при построении доверительных интервалов , при статистической проверке гипотез , при измерении линейной взаимосвязи между случайными величинами.
На практике, когда вместо точного распределения случайной величины в распоряжении имеется лишь выборка, стандартное отклонение, как и математическое ожидание, оценивают (выборочная дисперсия), и делать это можно разными способами. Термины «стандартное отклонение» и «среднеквадратическое отклонение» обычно применяют к квадратному корню из дисперсии случайной величины (определённому через её истинное распределение), но иногда и к различным вариантам оценки этой величины на основании выборки.
В частности, если x i {\displaystyle x_{i}} - i -й элемент выборки, n {\displaystyle n} - объём выборки, x ¯ {\displaystyle {\bar {x}}} - среднее арифметическое выборки (выборочное среднее - оценка математичекого ожидания величины):
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n) , {\displaystyle {\bar {x}}={\frac {1}{n}}\sum _{i=1}^{n}x_{i}={\frac {1}{n}}(x_{1}+\ldots +x_{n}),}то два основных способа оценки стандартного отклонения записываются нижеследующим образом.
Оценка стандартного отклонения на основании смещённой оценки дисперсии (иногда называемой просто выборочной дисперсией ):
S = 1 n ∑ i = 1 n (x i − x ¯) 2 . {\displaystyle S={\sqrt {{\frac {1}{n}}\sum _{i=1}^{n}\left(x_{i}-{\bar {x}}\right)^{2}}}.}Кроме того, среднеквадратическим отклонением называют математическое ожидание квадрата разности истинного значения случайной величины и её оценки для некоторого метода оценки . Если оценка несмещённая (выборочное среднее - как раз несмещённая оценка для случайной величины), то эта величина равна дисперсии этой оценки.
Правило трёх сигм
Правило трёх сигм () гласит: вероятность того, что любая случайная величина отклонится от своего среднего значения менее чем на 3 σ {\displaystyle 3\sigma } - P (| ξ − E ξ ∣< 3 σ) ≥ 8 9 {\displaystyle P(|\xi -E\xi \mid <3\sigma)\geq {\frac {8}{9}}} .
Климат
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой на равнине. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
Пример вычисления стандартного отклонения оценок учеников
Предположим, что интересующая нас группа (генеральная совокупность) это класс из восьми учеников, которым выставляются оценки по 10-бальной системе. Так как мы оцениваем всю группу, а не её выборку, можно использовать стандартное отклонение на основании смещённой оценки дисперсии. Для этого берём квадратный корень из среднего арифметического квадратов отклонений величин от их среднего значения.
Пусть оценки учеников класса следующие:
2 , 4 , 4 , 4 , 5 , 5 , 7 , 9. {\displaystyle 2,\ 4,\ 4,\ 4,\ 5,\ 5,\ 7,\ 9.}Тогда средняя оценка равна:
μ = 2 + 4 + 4 + 4 + 5 + 5 + 7 + 9 8 = 5 {\displaystyle \mu ={\frac {2+4+4+4+5+5+7+9}{8}}=5}Вычислим квадраты отклонений оценок учеников от их средней оценки.